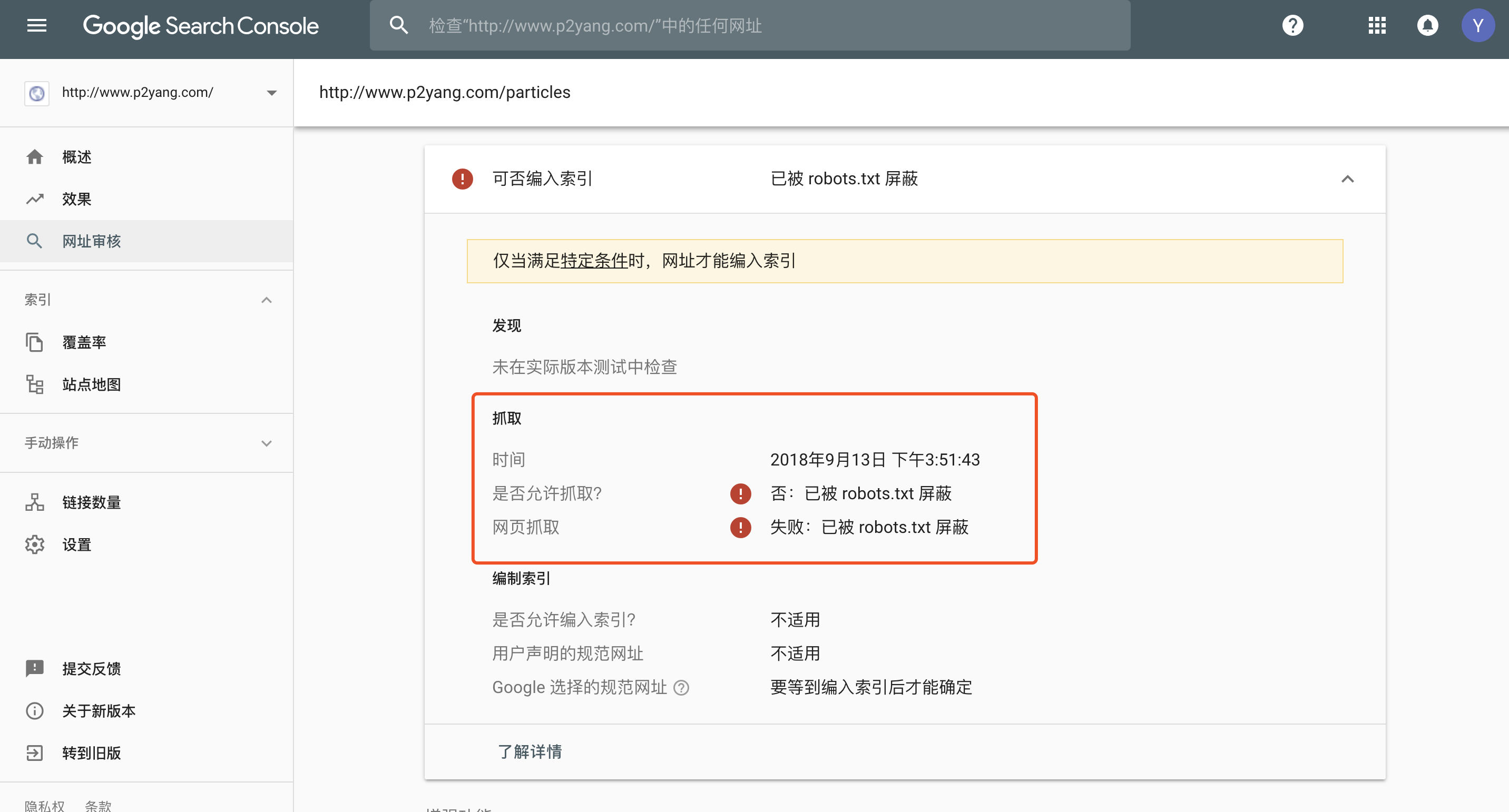
如果不想 Google 爬虫抓取某个页面,可以考虑添加 robots.txt 文件进行选择性屏蔽。
robots.txt文件位于您网站的根目录下,用于表明您不希望搜索引擎抓取工具访问您网站上的哪些内容。--- Google
一个示例
将 robots.txt 添加到网站根目录下,示例如下
User-agent: *
Disallow: /particles
Allow: /
# 本站暂时还未添加 sitemap
# Sitemap: http://www.p2yang.com/sitemap.xml
语法
robots.txt 文件中使用了以下关键字:
- User-agent:[必需,每条规则需要一个或多个] 此条规则所要应用到的搜索引擎“漫游器”(即网页抓取工具软件)的名称。Web Robots Database 和 Google 用户代理列表中列出了大多数用户代理名称。支持使用星号 (*) 通配符表示路径前缀、后缀或整个字符串。像下例中那样使用星号 (*) 可匹配所有抓取工具(各种 AdsBot 抓取工具除外,此类抓取工具必须明确指定)。(查看 Google 抓取工具名称列表。)
# Block all but AdsBot crawlers
User-agent: *
- Disallow:[每条规则需要至少一个或多个 Disallow 或 Allow 条目] 用户代理不应抓取的目录或网页(以相对于根网域的路径表示)。如果要指定网页,就应提供浏览器中显示的完整网页名称;如果要指定目录,则应以 / 标记结尾。支持使用星号 (*) 通配符表示路径前缀、后缀或整个字符串。
- Allow:[每条规则需要至少一个或多个 Disallow 或 Allow 条目] 上文中提到的用户代理应抓取的目录或网页(以相对于根网域的路径表示)。此指令用于替换 Disallow 指令,从而允许抓取已禁止访问的目录中的子目录或网页。如果要指定网页,就应提供浏览器中显示的完整网页名称;如果要指定目录,则应以 / 标记结尾。支持使用星号 (*) 通配符表示路径前缀、后缀或整个字符串。
- Sitemap:[可选,每个文件可包含零个或多个] 相应网站的站点地图的位置。此行不是必需的,您可酌情指定多个站点地图,并使用换行符分隔各个站点地图。站点地图是一种用于指示 Google 应抓取哪些内容的理想方式,但并不用于指示 Google 可以抓取或不能抓取哪些内容。详细了解站点地图。
有效性测试
发布后可使用官方提供的工具进行测试。
实际效果如下: